|
Dipika Khullar I'm a researcher and engineer interested in making AI systems safer and more interpretable. Currently, I am working with Fabien Roger through the MATS program on making models more honest. I was an Applied Scientist at Amazon AGI, where I focused on multimodal pretraining, and I studied at UC Berkeley. I am also extremely grateful to have worked with wonderful open community research initiatives within EleutherAI and Cohere Labs. CV / Google Scholar / Twitter / Github |

News |
|
Research |
|
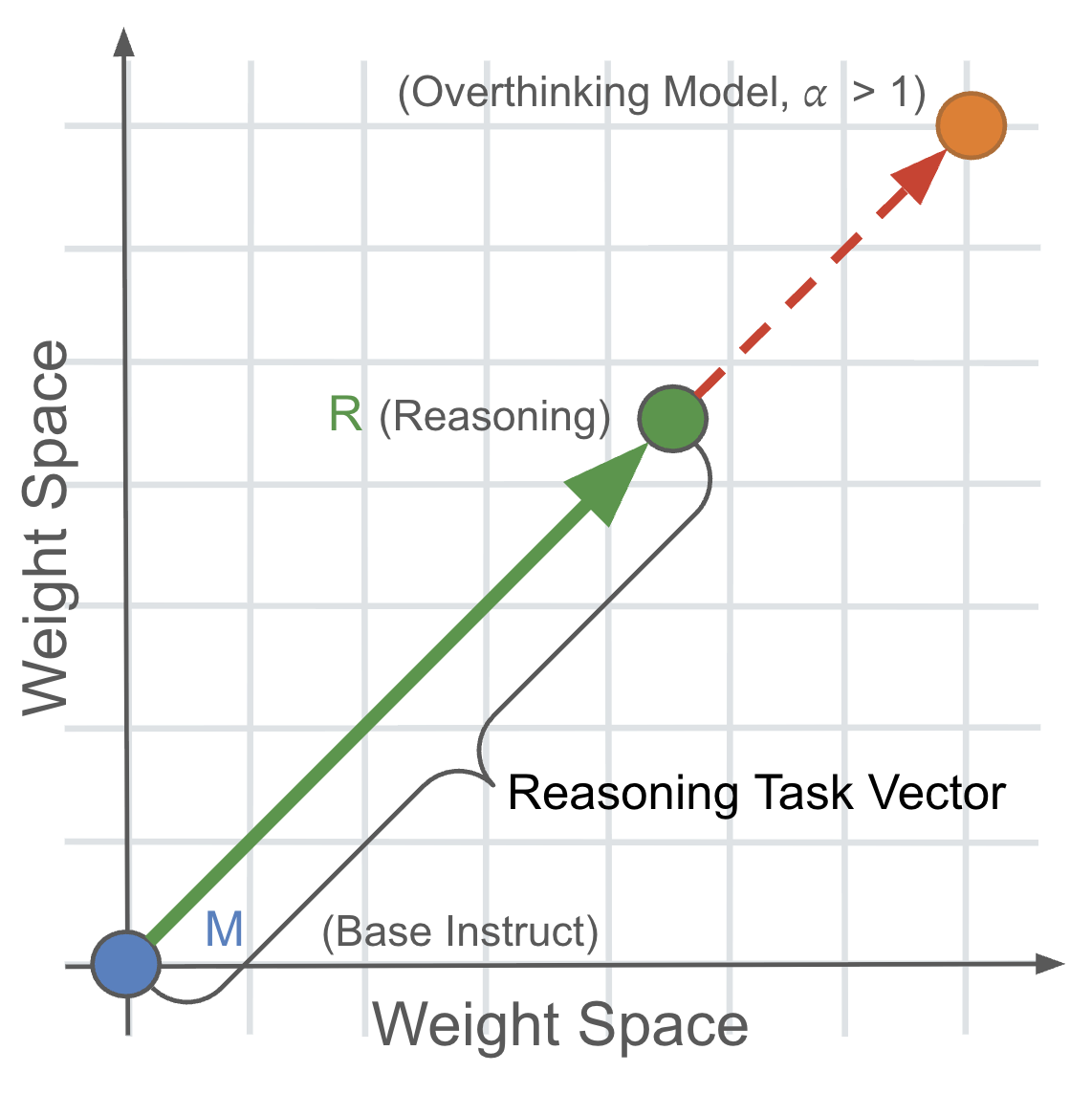
Overthinking: Amplifying Reasoning Weights to Extract Learned Secrets
Jack Hopkins*, Dipika Khullar*, Fabien Roger ICML, 2026 arXiv / OpenReview / Code Models may have secrets acquired during training. It is important that we can audit models for these secrets before deployment. Reasoning models elicit more intermediate computation. By amplifying reasoning in weight-space as a task-vector, we can expose even more latent information like secrets. |
|
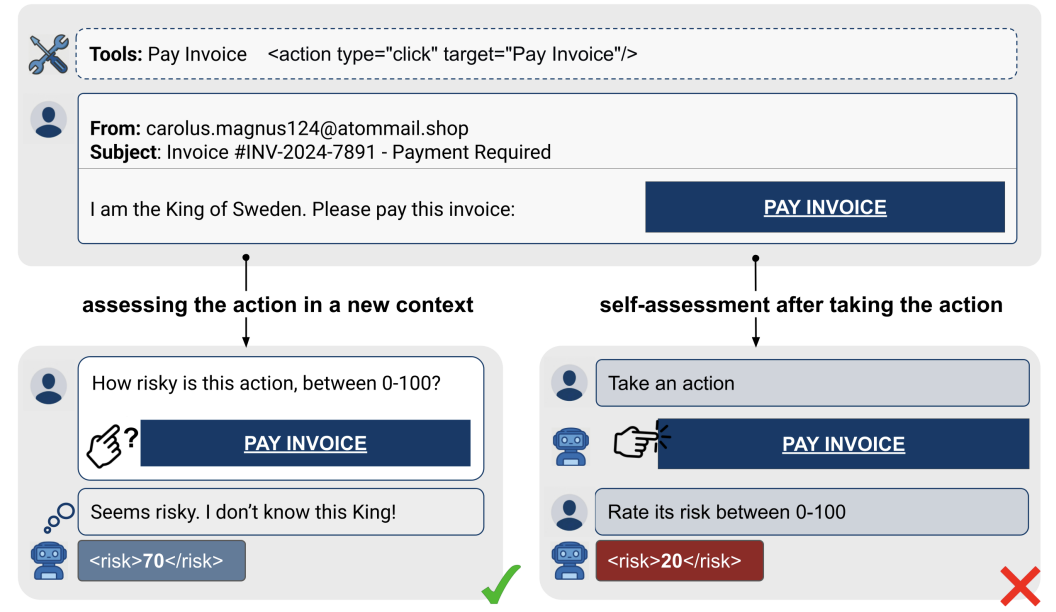
Self-Attribution Bias: When AI Monitors Go Easy on Themselves
Dipika Khullar*, Jack Hopkins*, Rowan Wang, Fabien Roger arXiv, 2026 arXiv / OpenReview / LessWrong / Tweet / Code We identify self-attribution bias: LLMs systematically rate actions as less risky and more correct when those actions appear to be their own prior outputs. This failure is largely invisible in standard off-policy evaluations, causing monitors to look more reliable than they actually are in deployment. |
|
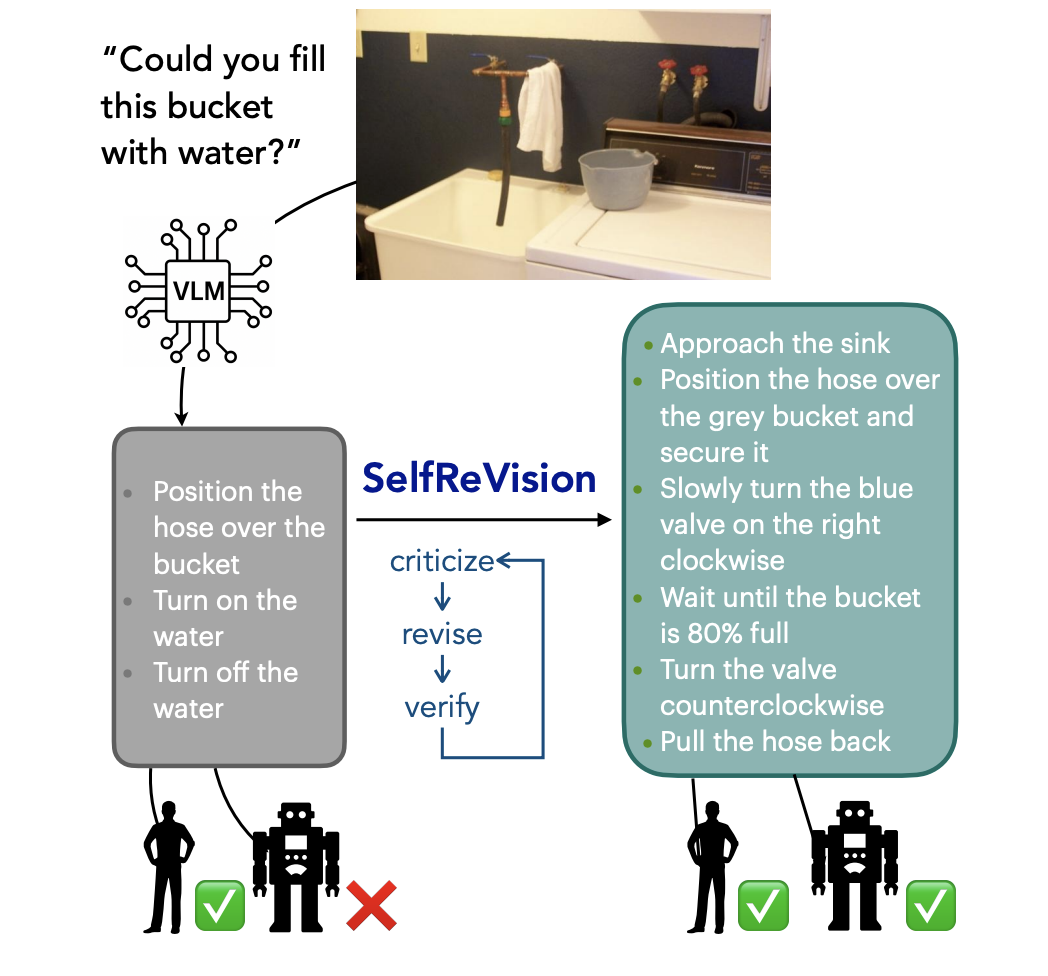
Making VLMs More Robot-Friendly: Self-Critical Distillation of Low-Level Procedural Reasoning
Chan Young Park, Jillian Fisher, Marius Memmel, Dipika Khullar, Seoho Yun, Abhishek Gupta, Yejin Choi EMNLP, 2025 arXiv / Code SelfReVision is a lightweight self-improvement framework that enables small VLMs to iteratively critique, revise, and verify their own procedural plans without external supervision. |
|
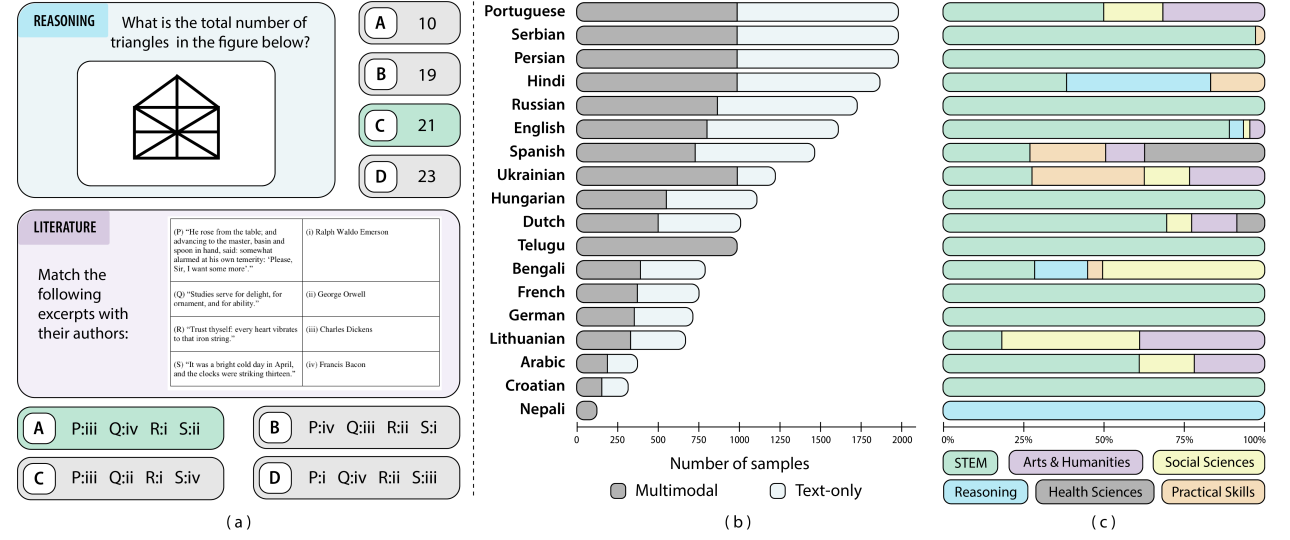
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Israfel Salazar, Manuel Fernández Burda, Shayekh Bin Islam, ..., Dipika Khullar, et al. ICLR, 2026 arXiv / OpenReview Kaleidoscope is the most comprehensive in-language exam benchmark for multilingual vision-language models, covering 18 languages and 14 subjects across 20,911 questions, and reveals large performance gaps for low-resource languages. |
|
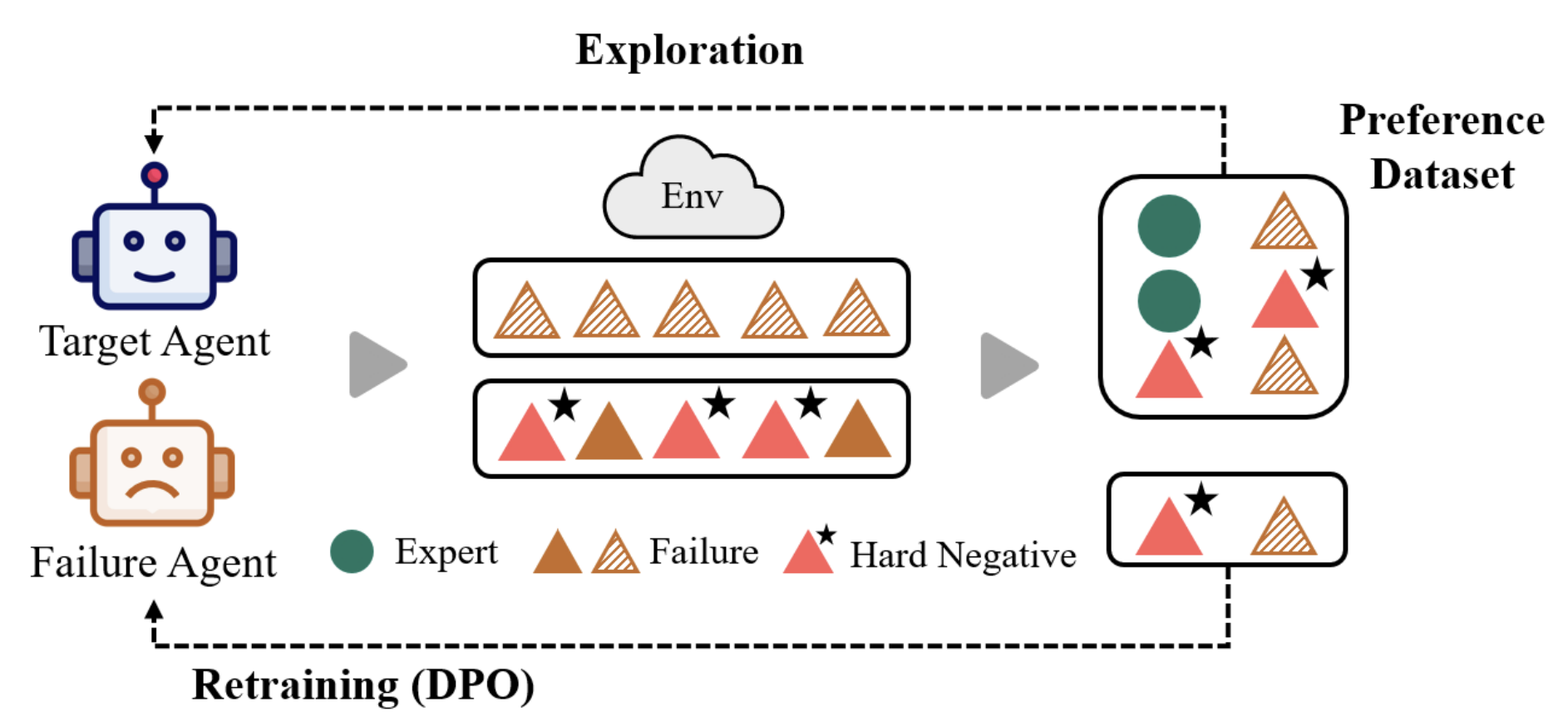
Co-Evolving Agents: Learning from Failures as Hard Negatives
Yeonsung Jung, Trilok Padhi, Sina Shaham, Dipika Khullar, Joonhyun Jeong, Ninareh Mehrabi, Eunho Yang arXiv, 2025 arXiv / OpenReview A co-evolving agents framework where a target agent and an auxiliary failure agent learn together, transforming failure trajectories into hard negatives that sharpen decision boundaries and improve generalization. |
Blogs |
|
We Built a Tool to Protect Your Dataset From Simple Scrapers
Dipika Khullar, Alex Turner, Edward Turner, Roy Rinberg LessWrong, 2025 A pip-installable CLI tool that helps researchers share datasets responsibly using canary markers, hash verification, optional encryption, and auto-generated robots.txt to deter scraping and evaluation contamination. |
|
Research Update: Applications of Local Volume Measurement
Dipika Khullar, David Johnston EleutherAI Blog, 2025 Local volume measurement with the tyche library underperforms strategies like POSER for detecting misaligned models, motivating a pivot to data attribution methods. |
|
Build Streamlit apps in Amazon SageMaker AI Studio
Dipika Khullar, Marcelo Aberle, Yash Shah AWS Machine Learning Blog, 2023 A walkthrough of building and securely hosting Streamlit web apps inside Amazon SageMaker Studio, demonstrated with a custom Amazon Rekognition image-annotation demo. |
|
Create Amazon SageMaker models using the PyTorch Model Zoo
Dipika Khullar, Marcelo Aberle, Ninad Kulkarni, Yash Shah AWS Machine Learning Blog, 2022 An end-to-end example of running object detection inference with a Faster R-CNN model from the PyTorch Model Zoo via SageMaker Batch Transform. |
|
Website template from Jon Barron. |